
Feed aggregator
EDITIONS EBR
A problem when ranking regression slopes over a database link
Extract a Node value from XML stored under BLOB in Oracle Tables has row 266 million rows
Big PL/SQL block passes wrong parameters for function call
How to connect SQL Developer using oracle wallet external password store
Dynamic Sql
Object Type Variables in Bulk Collect and FORALL
Insert Into Large Tables Takes Longer Time
Oracle's RDBMS approach to sizing the database server ( versus MongoDB's approach )
Inlining a function
Oracle EXPDP commands
The expdp (Data Pump Export) utility is used to export data and metadata from an Oracle database. It provides several command-line options to customize the export process. Below are some common expdp commands and their explanations:
Basic Syntax:
expdp [username/password] DIRECTORY=directory_name DUMPFILE=dumpfile_name LOGFILE=logfile_name [options]
Common Expdp Commands:
- Export a Full Database:
expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=full_db.dmp LOGFILE=full_db.log
- FULL=Y: Exports the entire database.
- Export a Specific Schema:
expdp system/password SCHEMAS=schema_name DIRECTORY=dpump_dir DUMPFILE=schema.dmp LOGFILE=schema.log
- SCHEMAS=schema_name: Exports a specific schema.
- Export Specific Tables:
expdp system/password TABLES=table1,table2 DIRECTORY=dpump_dir DUMPFILE=tables.dmp LOGFILE=tables.log
- TABLES=table1,table2: Exports specific tables.
- Export a Specific Table with Data and Metadata:
expdp system/password TABLES=table_name DIRECTORY=dpump_dir DUMPFILE=table.dmp LOGFILE=table.log
- TABLES=table_name: Exports a specific table.
- Export with Compression:
expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=full_db.dmp LOGFILE=full_db.log COMPRESSION=ALL
- COMPRESSION=ALL: Compresses all data during export.
- Export with Data Filtering (e.g., Export Data from a Specific Date):
expdp system/password TABLES=table_name DIRECTORY=dpump_dir DUMPFILE=table.dmp LOGFILE=table.log QUERY=table_name:"WHERE created_date > TO_DATE('2024-01-01', 'YYYY-MM-DD')"
- QUERY=table_name:"WHERE condition": Filters rows based on a condition.
- Export Metadata Only:
- expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=metadata.dmp LOGFILE=metadata.log CONTENT=METADATA_ONLY
- CONTENT=METADATA_ONLY: Exports only metadata (no data).
- Export Data Only:
expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=data_only.dmp LOGFILE=data_only.log CONTENT=DATA_ONLY
- CONTENT=DATA_ONLY: Exports only data (no metadata).
- Export a Database with a Specific Date Format:
expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=full_db.dmp LOGFILE=full_db.log PARALLEL=4
- PARALLEL=4: Uses 4 parallel threads for faster export.
- Export with a Job Name:
expdp system/password FULL=Y DIRECTORY=dpump_dir DUMPFILE=full_db.dmp LOGFILE=full_db.log JOB_NAME=export_full_db
- JOB_NAME=export_full_db: Assigns a name to the export job.
Additional Parameters:
- CONTENT: Specifies whether to export metadata only (METADATA_ONLY), data only (DATA_ONLY), or both (ALL).
- EXCLUDE: Excludes specific objects or object types from the export. Example: EXCLUDE=TABLE:"='table_name'".
- INCLUDE: Includes specific objects or object types in the export. Example: INCLUDE=TABLE:"IN ('table1', 'table2')".
- REMAP_SCHEMA: Remaps schema names. Example: REMAP_SCHEMA=old_schema:new_schema.
- REMAP_TABLESPACE: Remaps tablespace names. Example: REMAP_TABLESPACE=old_tablespace:new_tablespace.
Directory Object:
Before running expdp, ensure that the DIRECTORY object exists in the database and points to a valid filesystem directory where the dump files will be written.
CREATE OR REPLACE DIRECTORY dpump_dir AS '/path/to/directory';
Example Execution:
To execute an expdp command, open a command prompt or terminal and run the appropriate expdp command based on your requirements. Ensure you have the necessary privileges and that the Oracle environment variables (ORACLE_HOME and PATH) are set correctly.
Conclusion:
The expdp utility offers powerful options for exporting data and metadata from Oracle databases. By using the appropriate parameters and options, you can tailor the export process to meet specific needs and optimize performance.
unified audit on execute on procedure does not record in audit trail when error ORA-06550, PLS-00306
Options for Change Data Capture
Prevent future dates in for inspection_date column in table
Video on DataGuard Switchover -- with RAC and Single Instance
I've posted a demonstration of DataGuard Switchover, using RAC and Single Instance as the Primary/Standby pair.
Fundamentally, there is no difference if either or both of the databases are RAC or Single Instance.
A Switchover is a Graceful operation, with No-Data-Loss as the Primary sends the "End-Of-Redo Marker" to the Standby at which point Reversal of Roles happens. Therefore, you can execute Switchover between the two databases (servers / data centres / sites) multiple times without loss of data.
A Failover, on the other hand, involves data loss and the erstwhile Primary does not revert to a Standby role but must be recreated / refreshed as a Standby from the new Primary.
Getting inspiration from daily use (or not)
It’s been an odd few months on the content creation front. When Oracle Database 23c/23ai Free was released I was no longer under NDA for the shipped functionality, and I pushed out a glut of version 23 content here. Since then I’ve been waiting for the full on-prem release so I can publish the remaining … Continue reading "Getting inspiration from daily use (or not)"
The post Getting inspiration from daily use (or not) first appeared on The ORACLE-BASE Blog.Getting inspiration from daily use (or not) was first posted on September 1, 2024 at 9:11 am.©2012 "The ORACLE-BASE Blog". Use of this feed is for personal non-commercial use only. If you are not reading this article in your feed reader, then the site is guilty of copyright infringement.
Manage Feathers.js authentication in Swagger UI
In addition to my previous articles Add a UI to explore the Feathers.js API and Add authentication in a Feathers.js REST API, today, I will explain how to manage Feathers.js authentication in Swagger UI and make it simple for our users.
After enabling authentication on API methods, as a result, using Swagger UI for testing is difficult, if not impossible. To solve this problem, Swagger needs to support authentication.
In this article, I will reuse the code from my previous articles.
First step: add authentication specifications to the applicationFor Swagger UI to handle API authentication, I need to update the specifications in the app.ts file. Therefore, in the specs object, I add the components and security parts:
app.configure(
swagger({
specs: {
info: {
title: 'Workshop API ',
description: 'Workshop API rest services',
version: '1.0.0'
},
components: {
securitySchemes: {
BearerAuth: {
type: 'http',
scheme: 'bearer',
},
},
},
security: [{ BearerAuth: [] }],
},
ui: swagger.swaggerUI({
docsPath: '/docs',
})
})
)This new configuration, general to the API, tells Swagger that authenticated methods will use a Bearer token.
Second step: define documentation for authentication methodsThe authentication service generated by the CLI does not contain any specifications for Swagger UI, which results in an error message being displayed on the interface. So I’m adding the specifications needed by Swagger to manage authentication methods:
export const authentication = (app: Application) => {
const authentication = new AuthenticationService(app)
authentication.register('jwt', new JWTStrategy())
authentication.register('local', new LocalStrategy())
// Swagger definition.
authentication.docs = {
idNames: {
remove: 'accessToken',
},
idType: 'string',
securities: ['remove', 'removeMulti'],
multi: ['remove'],
schemas: {
authRequest: {
type: 'object',
properties: {
strategy: { type: 'string' },
email: { type: 'string' },
password: { type: 'string' },
},
},
authResult: {
type: 'object',
properties: {
accessToken: { type: 'string' },
authentication: {
type: 'object',
properties: {
strategy: { type: 'string' },
},
},
payload: {
type: 'object',
properties: {},
},
user: { $ref: '#/components/schemas/User' },
},
},
},
refs: {
createRequest: 'authRequest',
createResponse: 'authResult',
removeResponse: 'authResult',
removeMultiResponse: 'authResult',
},
operations: {
remove: {
description: 'Logout the current user',
'parameters[0].description': 'accessToken of the current user',
},
removeMulti: {
description: 'Logout the current user',
parameters: [],
},
},
};
app.use('authentication', authentication)
}The authentication.docs block defines how Swagger UI can interact with the authentication service.
Third step: add the security config into the serviceAt the beginning of my service file (workshop.ts), in the docs definition, I add the list of methods that must be authenticated in the securities array:
docs: createSwaggerServiceOptions({
schemas: {
workshopSchema,
workshopDataSchema,
workshopPatchSchema,
workshopQuerySchema
},
docs: {
// any options for service.docs can be added here
description: 'Workshop service',
securities: ['find', 'get', 'create', 'update', 'patch', 'remove'],
}As a result of the configuration, new elements appear on the interface:
- The Authorize button at the top of the page
- Padlocks at the end of authenticated method lines
- A more complete definition of authentication service methods
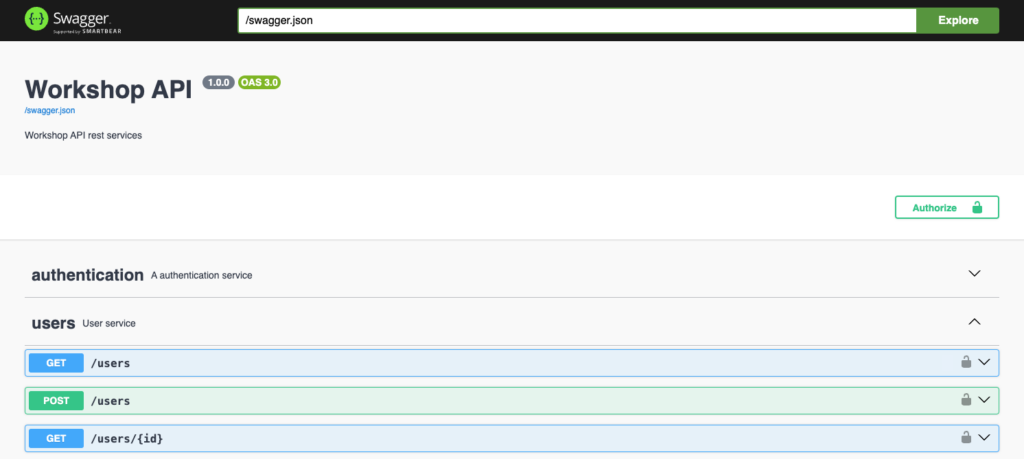 Obtain an access token with the UI
Obtain an access token with the UI
First, I need to log in with my credentials to get a token. After that, the bearer token will be used in the next authenticated calls:
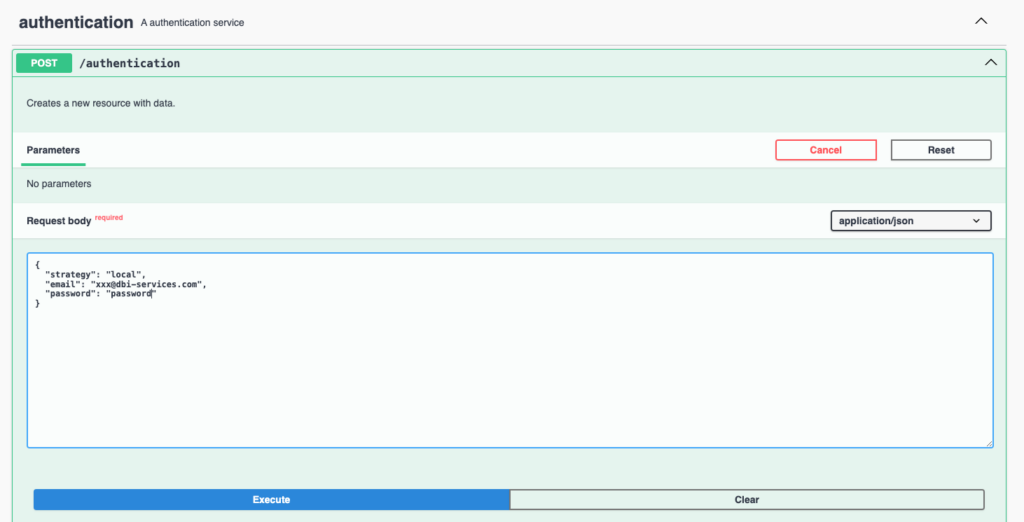
The JSON object sent in the request body contains the identification information. In return, we’ll get an accessToken useful for the next calls:
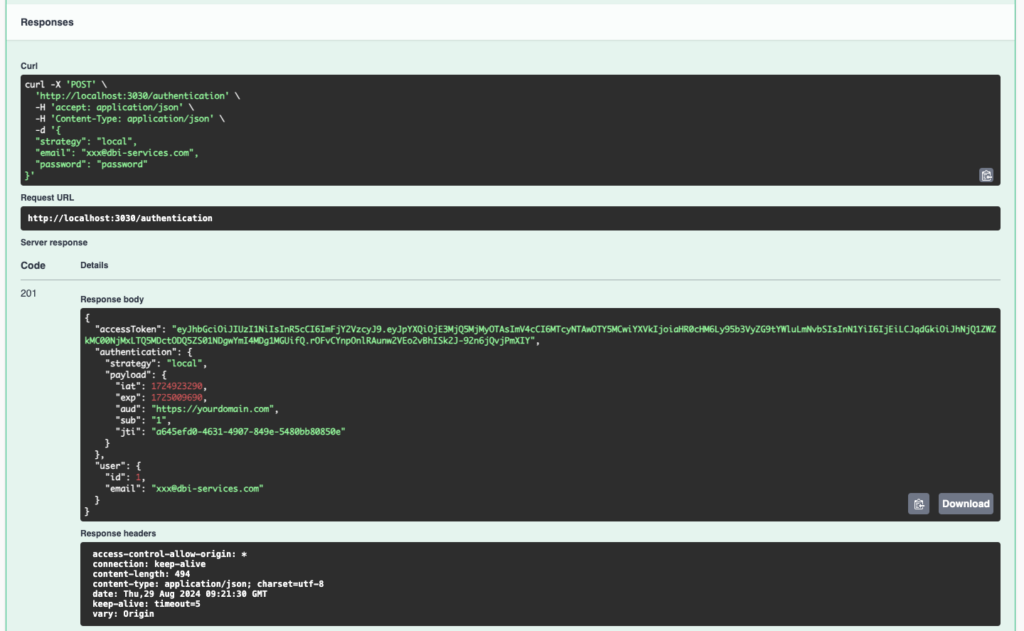 Second step, define the bearer token for authenticated requests
Second step, define the bearer token for authenticated requests
Each call to an authenticated method requires the token to be sent in the http headers. We therefore register the token in Swagger UI by clicking on the Authorize button and paste the token obtained during the authentication step:
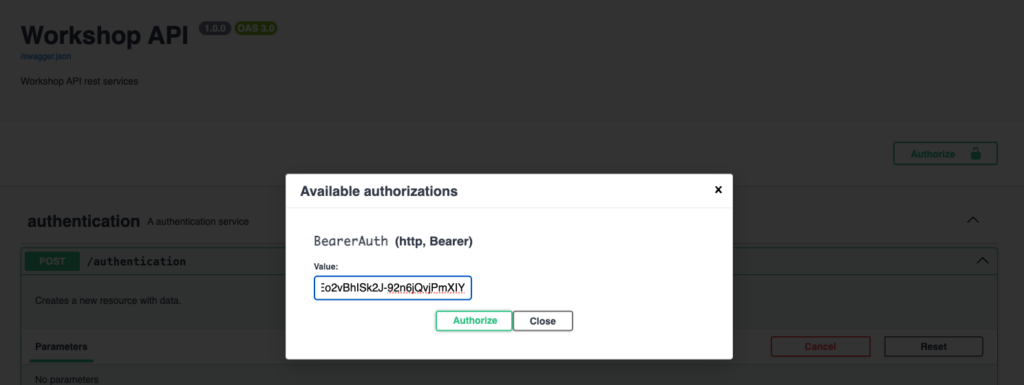 Testing authenticated methods
Testing authenticated methods
Once the token has been entered into Swagger UI, I use the methods without worrying about authentication:
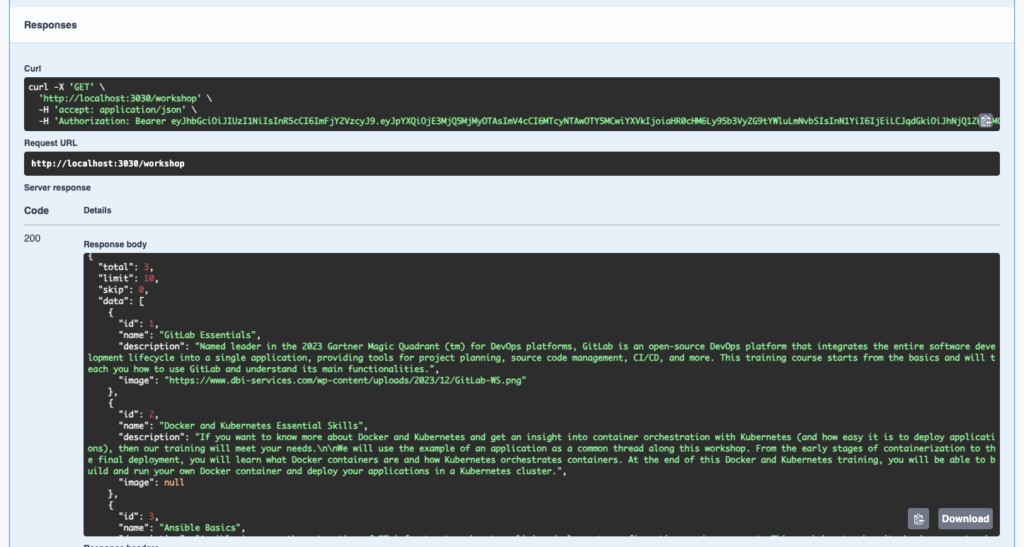
Swagger UI sends the token in the http headers to authenticate the request. Then the api returns the data:
 Conclusion
Conclusion
Managing Feathers.js authentication in Swagger UI is entirely possible. With a little extra configuration, it becomes easy to use authentication and authenticated methods. It’s even simple to test all API methods and document their use.
L’article Manage Feathers.js authentication in Swagger UI est apparu en premier sur dbi Blog.
DBMS_XMLGEN limited workaround for converting LONG columns into CLOBs
If you landed here is because you hit the problem of dealing with LONG columns.
There are some good articles elsewhere about how to tackle this old problem, my contribution in this case consists in advising about some limitations that apparently have been overlooked when using the same technique explained below.
It's a mystery to me why after so many years we can't rid of this annoyance once for good, why not "simply" adding a CLOB column equivalent at least in the case of data dictionary columns?
Come on!
I needed to extract the content of the TEXT column from DBA_VIEWS and DBA_MVIEWS, possibly without having to pass through an INSERT into a table (using function TO_LOB), which is the best workaround in case you deal with static data, for one-off operations.
I stumbled upon an old video of Connor McDonald showing how to extract the content of a LONG column exploiting the XML API DBMS_XMLGEN.GETXMLTYPE. This trick seemed to save the day after some adaptation for my case, and actually I was almost ready to celebrate when I started hitting some errors while doing further tests.
To cut a long story short, eventually I encountered the following problems:
- API documentation for version 19c of DBMS_XMLGEN.SETCONVERTSPECIALCHARS is incorrect as it mentions a parameter "conv" but the real parameter name is "replace". This typo is still present in the latest version of the documentation of 23ai.
- DBMS_XMLGEN.GETXMLTYPE and DBMS_XMLGEN.GETXML won't perform special characters escaping via DBMS_XMLGEN.SETCONVERTSPECIALCHARS if the column type is LONG.
I was getting parsing errors when using Connor's EXTRACTVALUE technique because the XML document contained < or > as spare characters in the source (as in WHERE conditions inside the query source).
- DBMS_XMLGEN.GETXMLTYPE and DBMS_XMLGEN.GETXML will truncate the content to the first 32K for LONG columns.
Problem #1 was easily solved, problem #2 was solved extracting the data using REGEXP_SUBSTR instead of EXTRACTVALUE, but this was possible because I was working on a XML document containing a single ROW tag at a time. For multiple rows this solution will not work.
FUNCTION long2clob
( p_qry in clob, -- must return a single row!
p_col in varchar2)
RETURN CLOB
IS
c CLOB;
BEGIN
c := regexp_substr(
dbms_xmlgen.getxml(p_qry),
'(<ROW>.*<' || p_col || '>(.*)</' || p_col || '>.*</ROW>)',
1,
1,
'cn'
,2
);
return c;
END long2clob;Problem #3 remains, unless LONG columns are less than 32K.
Unfortunately we do have some views exceeding 32K of source, but considering the usage of this function I'll probably live with this limitation for the moment.
By the way, SQLDeveloper won't allow you to edit a view larger than 32K, and to me this sounds like an invitation to avoid such situations.
Finally, I also tried to see what happens when you supply a LONG column to function JSON_OBJECT, unfortunately it returns the exception:
ORA-40654: Input to JSON generation function has unsupported data type.
That's all folks!
(quote)